Featured post
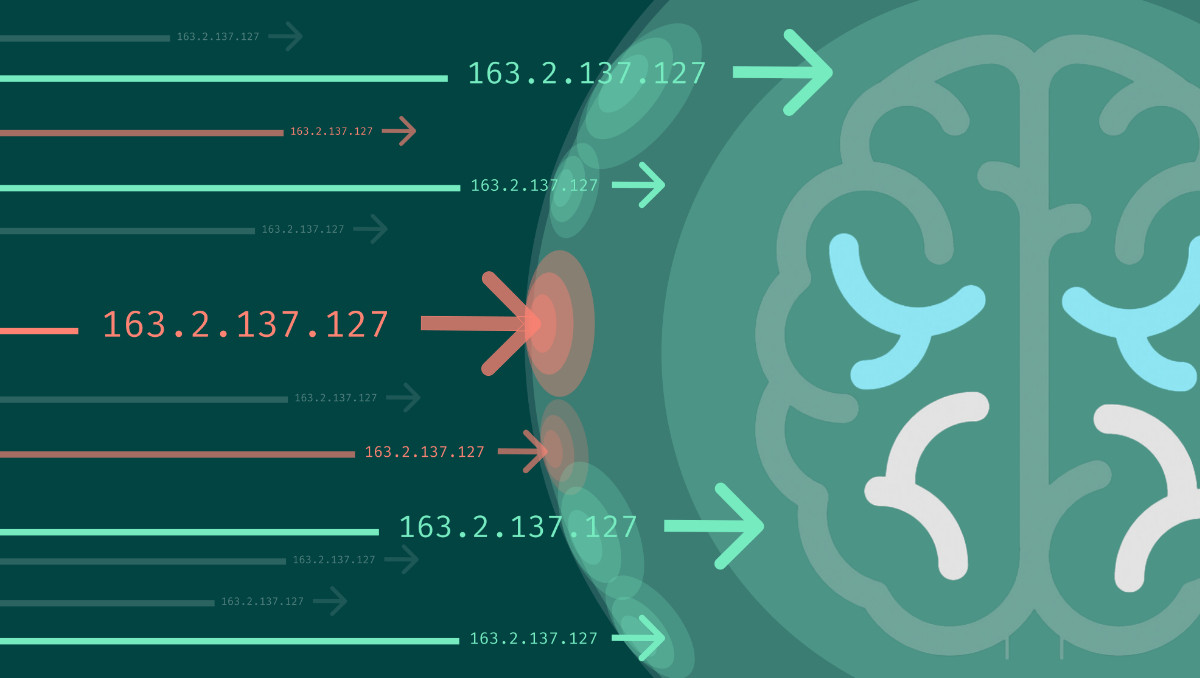
Stop Bad IPs Continually with Globalscape’s Threat Brain Integration
In today’s cybersecurity environment, every bit of proactive defense helps to deter bad actors from entering and hanging around with potentially malicious intent.
In today’s cybersecurity environment, every bit of proactive defense helps to deter bad actors from entering and hanging around with potentially malicious intent.

Protect sensitive data with real-time threat protection and advanced encryption, ensuring secure, compliant file transfers across every environment.

Let’s be honest: in banking and finance, “good enough” file transfer is usually a liability wearing a business-as-usual badge.

Why secure file transfer continues to break across industries—and how modern MFT improves visibility, control, and resilience without disrupting operations.

Explore why modern organizations are rethinking MFT as a core layer of security, control, and operational resilience.

Your MFT may check every box—but that doesn’t mean it’s secure in practice. Learn where risk actually lives and what most teams overlook.

Explore how MFT detects suspicious activity, limits exposure, and responds to security threats through architecture, automation, and visibility.

Are organizations ready for modern MFT? Explore why legacy file transfer platforms are falling behind—and what IT teams now expect from next‑generation MFT.

As file transfers scale, governance often falls behind. See how enterprise MFT reduces risk, improves reliability, and simplifies audits across large environments.

PCI DSS risk often starts in DEV and TEST. Discover how policy driven file transfers help control data movement and reduce PCI DSS scope.

Organizations using Globalscape EFT rely on the platform to move sensitive files efficiently, securely, and in line with strict internal and external compliance requirements. With the release of Globalscape EFT 8.3.2, Fortra MFT continues to advance this mission.

A trusted Managed File Transfer (MFT) solution safeguards the secure, compliant, and reliable movement of sensitive data across the enterprise, making it mission-critical technology for organizations of almost any size. With so much riding on this foundation, it’s important to understand the key considerations that shape MFT pricing and what organizations should evaluate before investing.

Downtime costs enterprises millions. Learn why zero downtime upgrades and high-availability MFT are now essential for resilience, compliance, and always on operations.
Page 1 of 9